ZadanieWeź ołówek i określ cele stron www, które chciałbyś stworzyć.Następnie wybierz strony www władz lokalnych w Polsce (mogą to być strony należące do twoich władz lokalnych) lub za granicą, obejrzyj je i napisz, jak ci się wydaje, co brano pod uwagę (jaki był cel) tworząc te strony. Czy ten cel jest czytelny? Jeżeli zamierzono kilka celów, to czy zostały one oddzielnie zidentyfikowane na tej stronie? |
| Do początku strony | Do strony domowej |
Intranety i Internet
Organizacje nie tylko działają w obrębie Internetu, również rozwijają i utrzymują zamknięte sieci Intranet - systemy wykorzystujące protokół TCP/IP, ale ograniczone do osób należących do danej organizacji i posiadających autoryzowany dostęp do systemu. Intranet nie musi mieć dostępu do Internetu, przeważnie interakcja jest jednostronna - pracownik instytucji ma dostęp do źródeł internetowych, lecz ludzie nie należący do danej organizacji nie posiadają dostępu do wewnętrznych stron intranetowych.
Intranet projektuje się zazwyczaj w taki sposób, aby dostęp do wewnętrznych źródeł informacji był jak najbardziej przyjazny dla użytkownika. Powinniśmy sobie jednak zadać to samo co wcześniej pytanie: "Jakie jest przeznaczenie tego miejsca?" Władze administracji lokalnej są organizacjami o złożonej strukturze. Poszczególne jednostki często opracowują w różny sposób zestawienia statystyczne dla różnych oddziałów administracji państwowej a także podlegają one różnym przepisom prawnym, co oznacza, ze utrzymują stosunki z różnymi agendami administracji państwowej. Jak widać skuteczny przepływ informacji wewnątrz organizacji nie jest błahym problemem, a intranet może być częścią jego rozwiązania.
| Do początku strony | Do strony domowej |
Języki znaczników tekstowych
Wprowadzenie
Dawniej termin znakowanie (markup) stosowano do opisu adnotacji lub innych znaków w obrębie tekstu z zamiarem poinstruowania zecera (składacza) lub maszynistki, w jaki sposób poszczególne akapity powinny być drukowane lub złożone. Przykłady zawierają faliste podkreślenia, które wskazują tłusty druk, specjalne symbole dla ustępów dokumentu, które mają być pominięte lub drukowane określoną czcionką itd. W chwili gdy formatowanie i drukowanie tekstów zostało zautomatyzowane, pojęcie to rozciągnięto na różnego rodzaju znaczniki wstawiane do tekstów elektronicznych wpływające na formatowanie, drukowanie lub przetwarzanie innego rodzaju.
[http://www.uic.edu/orgs/tei/sgml/teip3sg/SG.htm]
Powyższa definicja mówi, w zasadzie, wszystko co się powinno wiedzieć o "języku" znaczników tekstowych (mark-up language): jest to system umożliwiający określenie tego, w jaki sposób strona tekstu powinna wyglądać na wydruku (wydawcy używają SGML np. do wydawania książek i czasopism), lub na ekranie komputera - HTML jest "językiem" znaczników tekstowych dla sieci www. Użyłem cudzysłowu dla słowa "język", aby zwrócić uwagę na okoliczność, że te zestawy kodów i towarzyszące im zasady nie są prawdziwymi językami programowania; są one, jak wspomniałem, zbiorem kodów, które określają jak dany tekst powinien wyglądać. Najprostszym sposobem zaprezentowania tego będzie pokazanie kodu w małym fragmencie tekstu - w tym wypadku kod to HTML. Jeżeli chcę aby słowo było przedstawione kursywą umieszczam je pomiędzy dwoma znacznikami:
<i> HTML </i>
a rezultat wygląda następująco:
HTML
SGML
SGML - standardowy uogólniony język znaczników (Standard Generalized Mark-up Language) jest "matką" języka znaczników, którego korzenie sięgają GML (Generalized Markup Language) opracowanego w 1969 r. przez Charlesa Goldfarba. Działania w kierunku utworzenia standardowego języka znaczników zaczęły się w 1978 r. kiedy Komitet Przetwarzania Informacji Amerykańskiego Instytutu Normalizacyjnego - ANSI (American National Standard Institute) powołał Komitet ds. Języków Komputerowych do Przetwarzania Tekstu (Computer Languages for the Processing of Text) z Goldfarbem jako członkiem. Następnie mianowano go kierownikiem projektu zajmującego się standardowym "językiem" do opisu tekstu opartym na GML. Pierwszy szkic roboczy standardu SGML został opublikowany w 1980 r. Trzy dalsze szkice robocze zostały przedstawione w 1984 r. Dziś projekt pod patronatem Międzynarodowej Organizacji Normalizacyjnej - ISO (International Organization for Standardization) rozpoczął regularne doroczne spotkania jako ISO/IEC JTC1/SC18/WG8. Propozycja dla standardu międzynarodowego została opublikowana w 1985 r., a sam standard międzynarodowy opublikowano w październiku 1985 r. Ostateczny tekst został wydany w 1986 r. jako ISO 8879:1986.
Podczas tego kursu nie będziemy zbyt głęboko wchodzić w szczegóły SGML, tym bardziej, iż pewne założenia będą się powtarzać w HTML i XML. Aplikacja napisana w SGML składa się z 4 części:
- deklaracji, która określa jakie znaki formatujące i ograniczniki (znaki typu < i >) mogą pojawić się w aplikacji.
- Definicji Typu Dokumentu (The Document Type Definition - DTD) określający syntaktykę elementów SGML czyli zasady definiujące w jaki sposób można używać elementów.
- specyfikacji, która określa znaczenie symboli (markup).
- dokumentu wraz ze znakami formatującymi (markup). Każdy dokument zawiera odwołanie do DTD jaki ma być użyty przy interpretacji.
| Do początku strony | Do strony domowej |
HTML
HTML jest czasem opisywany jako część, podzbiór SGML, co nie jest
zupełnie prawdą: HTML został zdefiniowany za pomocą SGML.
Definicję taką nazywamy Definicją Typu Dokumentu (The Document Type Definition - DTD) dla dokumentów hipertekstowych.
Wiele edytorów automatycznie umieszcza w pierwszej linii kod określający DTD.
Oto przykład takiej definicji:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
mówiącej nam, iż jest to dokument hipertekstowy, stworzony zgodnie ze standardem "HTML 4.0" oraz określający język angielski jako język używany do zdefiniowania tego szablonu.
Oczywiście nie jest to miejsce na pełny kurs HTML, można znaleźć wiele doskonałych materiałów na ten temat w Internecie. Przykładem może być kurs "Wprowadzenie do HTML", który znajdziemy wśród linków, na końcu tego modułu.
Główna idea użycie tagów HTML została przedstawiona w poniższym przykładzie. W pierwszej linii występuje omówiona już definicja dokumentu (DTD), następnie jest tag <html>, który rozpoczyna dokument hipertekstowy. W sekcji <head> ... </head> zawarta jest informacja, która nie pojawi się na ekranie (np. zobacz paragraf o 'meta-tagach'). W części <body> ...</body> znajduje się główna część dokumentu hipertekstowego, zawierająca wszystkie informacje, które zostaną wyświetlone na ekranie. Ostatni znacznik </html> oczywiście kończy dokument hipertekstowy.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Untitled</title>
</head>
<body>
</body>
</html>
Podstawowymi tagami występującymi w części BODY (tzn. <BODY> tutaj !!! </BODY>) są
NAGŁÓWKI (<H1>, <H2>, <H3> itd.), PARAGRAFY (tzn. <P> paragraf </P>),
LISTY (np. listy uporządkowane i nieuporządkowane tworzone za pomocą tagów <OL> lista </OL> lub <UL> lista </UL>) oraz TABLICE,
których składnia została opisana w dalszej części tego modułu.
Przewodnik NSCA
po HTML może być bardzo dobrym wstępem do poznania systemu tagów występującego w języku hipertekstowym.
Rodzina 'X'ML: XML, XHTML, XHML
To co nazwałem rodziną 'X' ML jest grupą języków znakowych, które zostały stworzone, aby poprawić mankamenty występujące w HTML. Moim zdaniem oznacza to, iż języki te są bardziej skomplikowane niż HTML, który w wersji 4.0 wydaje się być dość jasno zdefiniowanym. Z punku widzenia osoby tworzącej strony WWW, a w szczególności e-commerce, głównym ograniczeniem tego standardu jest stała ilość tagów. Wynikiem tego jest brak możliwości rozszerzenia funkcjonalności aplikacji lub stron WWW.
eXtensible Mark-up Language - XML (wolne tłumaczenie: Rozszerzalny Język Znakowy) jest definiowany w różny sposób: czasem określa się go jako podzbiór, część SGML, czasem jako 'aplikacyjny profil' SGML (cokolwiek to dokładnie znaczy, nie jestem pewny więc preferuje pierwsze określenie). Różnica pomiędzy XML i HTML została opisana w poniższym cytacie :
XML nie określa ani semantyki, ani też zbioru tagów. Tak naprawdę XML jest prawdziwym meta-językiem, którego zadaniem jest opisywanie języków znakowych. Innymi słowym XML daje możliwość definiowania tagów i strukturalnych zależności między nimi. Ponieważ nie ma z góry zdefiniowanego zbioru tagów, nie może więc być przyjętej semantyki dla tychże tagów. Cała semantyka dokumentów napisanych w XML bedzię zdefiniowana dopiero przez aplikacje, która będzie przerabiać dany plik, lub też style kaskadowe.
[Norman Walsh Co to jest XML?]
Kluczową własnością XML jest to, iż definicja tagów jest pod wyłączną kontrolą osoby tworzącej dany dokument. Daje to możliwość definiowania zawartości strony lub jej fragmentu . Oto prosty przykład :
<letter> <to1>Henry Livings</to1> <to2>Big Computers</to2> <to3>407 High Street</to3> <to4>Croydon</to4> <date>1st March 2001</date> <subject>Payment for order</subject> <text>[Text of the letter]</text> <salut>Yours faithfully</salut> <from>Martin Bryan</from> <desig>Sales Manager</desig> </letter>
Oczywiście organizacja W3C nie może pozwolić każdej osobie na tworzenie własnych tagów XML dla niezależnego użycia: powinna zostać stworzona centralna organizacja, która ustali pewien standard, który zostanie przyjęty przez wszystkich. Dodatkowo jednostka ta będzie odpowiedzialna za tworzenie zbiorów Document Type Definition (DTD), które formalnie zdefiniują zależności pomiędzy elementami w różnego rodzaju dokumentach. Na przykład, DTD dla powyższego dokumentu LETTER mógłby wyglądać tak :
<!DOCTYPE letter [ <!ELEMENT letter (to1, to2, to3, to4, date, subject?, salut, from, desig, para+) > <!ELEMENT para (#PCDATA) > <!ELEMENT to1 (#PCDATA) > <!ELEMENT to2 (#PCDATA) > <!ELEMENT to3 (#PCDATA) > <!ELEMENT to4 (#PCDATA) > <!ELEMENT date (#PCDATA) > <!ELEMENT subject (#PCDATA) > <!ELEMENT salut (#PCDATA) > <!ELEMENT from (#PCDATA) > <!ELEMENT desig (#PCDATA) > ]>
Znak zapytania po słowie "subject" (temat) wskazuje iż, to pole jest opcjonalne, natomiast 'para+' oznacza, iż list ten składa się z przynajmniej jednego paragrafu. Słowo #PCDATA wskazuje, iż dane w tym polu będą zawierały ciąg znaków.
Oczywiście XML w szybkim tempie rozwija się i staje się bardziej złożony. Jest to spowodowane pojawianiem się nowych atrybutów w poszczególnych elementach określających np. czy dany element ma być formatować jako kursywa (italic) czy może jako tekst pogrubiony (bold). Jak szybko XML zajmie dominującą pozycję na rynku języków stosowanych do tworzenia stron WWW zależy między innymi od tego jak szybko ludzie zajmujący się tworzeniem serwisów WWW lepiej poznają tak złożony system.
Złożoność XML nie kończy się na DTD: język ten posiada własne style kaskadowe XSL [nie mówiliśmy o stylach kaskadowych CSS występujących w HTML, CSS jest to standard pozwalający na określenie domyślny wartości dla różnych argumentów różnych tagów np. koloru, czcionki, marginesów itp.], na podstawie XML tworzone są również inne języki posiadające inne funkcje. Oto cytat na temat języka nazywanego XML Path:
"XPath jest wynikiem pracy podjętej w celu zapewnienia wspólnej syntaktycznej i semantycznej funkcjonalności występującej w transformacjach XML[XMLT] i XPointer. Podstawowym celem XPath jest zaadresowanie pewnych części dokumentu napisanego w XML. W celu osiągnięcia tego celu utworzone nowe funkcje pozwalające na wykonywanie operacji na łańcuchach znaków, liczbach oraz zmiennych logicznych. XPath używa prostej, nie XML'owej składni, w celu ułatwienia obsługi XPath w pracy z adresami URL i wartościami atrybutów XML'owych. XPath działa na abstrakcyjnych, logicznych strukturach dokumentu XML. XPath wzięło swoją nazwę od sposobu jego użycia - poprzez użycie ścieżki jako notacji wykorzystywanej przy nawigacji w hierarchicznej strukturze dokumentu napisanego w XML. "
XPointer:
"...w szczególny sposób uwzględnia specyficzne odwołanie do elementów, ciągów znaków, "elementów wyboru" i innych części dokumentu XML, bez względu na to czy posiadają one wyraźnie przyznany atrybut ID czy też używają odwołań do poszczególnych części dokumentu. Xpointer wykorzystuje różne własności dokumentu takie jak typ elementu, wartość atrybutu, zawartość, relatywna pozycja oraz uporządkowanie."
i XLink:
"określa konstrukcję, która może być zanurzona w dokumencie XML, aby opisać zależności, połączenia pomiędzy obiektami. XLink używa XML'owej syntaktyki, aby stworzyć strukturę, która może opisywać proste linki dzisiejszego HTML jak również bardziej złożone typy linków."
Moim zdaniem w przyszłości XML będzie prawdopodobnie używany tylko przez osoby, które zajmują się profesjonalnym tworzeniem serwisów WWW. "Amatorom" wystarczy zapewne stworzenie stron w stosunkowo prostym HTML, chociaż XML jest swego rodzaju krokiem do przodu. Jednak dokładniejsze poznanie XML wymaga poświęcenia dłuższego okresu czasu.
Oczywiście używanie XML zależy również od przeglądarki WWW, którą dysponujemy - programy najnowszej generacji pozwalają nam tylko na częściową interpretację tagów XML. Tak więc dopóki wszystkie przeglądarki nie będą poprawnie obsługiwać tego standardu, nie warto go implementować.
XHTML
XHTML jest to HTML w wersji 4.O opracowany w XML. Głównym celem powstania XHTML było stworzenie języka pomocnego w tworzeniu stron WWW w XML, z jednoczesnym zachowaniem kompatybilności z HTML w wersji 4.0. XHTML uważany jest jako krok w kierunku uznania XML jako standardu do tworzenia stron WWW.
XHML
W przyszłości XHML ma szansę zostać najpopularniejszym językiem wykorzystywanym do tworzenia stron WWW. Główną jego zaletą jest to, iż jest to język prostszy od XHTML ale w pełni z nim kompatybilny. Dodatkowo XHML jest związany z istnieniem preprocesora HTML nazwanego sh. Jego zadanie polega na odczytaniu pliku tekstowego i wyprodukowanie tagów XHML i HTML 4.0.
| Do początku strony | Do strony domowej |
Znalezienie dobrego edytora HTML
Najprostszym edytorem HTML jaki można stosować jest dowolny program pozwalający na pisanie zwykłego tekstu w kodach ASCI - jednym z nich jest Notatnik (Notepad), będący standardowym wyposażeniem komputerów osobistych (PC) działających w systemie Windows. W rzeczywistości, kiedy klikniemy na menu «Widok» Internet Explorera i wybierzemy «Dokument źródłowy» (Source) tym co pojawia się na ekranie jest tekst opatrzony kodami umieszczony w Notatniku. Wielu doświadczonych twórców stron www "piszących" w html nie używa innych narzędzi. Niektórzy programiści używają także oprogramowania do edycji, które tworzy proste pliki tekstowe (.txt). Używają ich jako plików html, po prostu zmieniając przyrostek .txt na .htm lub .html, w ten sposób wszystkie wyszukiwarki będą w stanie odczytać takie pliki.
Niemniej istnieją wyspecjalizowane edytory html, które ułatwiają zadanie wstawiania właściwych znaczników w dokumencie i pozwalają na prostszy sposób tworzenia tabel, formularzy oraz list. Mogą one zawierać procedury weryfikacji sprawdzające czy użyte kody są właściwe oraz czy odpowiadają bieżącym normom.
Niektóre edytory są oprogramowaniem bezpłatnym, a niektóre są chronione prawem autorskim, jeszcze inne są wersjami produktów komercyjnych, a inne są nimi w pełni. Oznacza to, że jest sporo "produktów" do przetestowania zanim się podejmie decyzję, który jest najodpowiedniejszy. Oczywiście "uproszczona" wersja Microsoft Front Page jest w pakiecie Microsoft Office i można z niej korzystać.
Mamy do czynienienia z różnego rodzaju narzędziami programowymi. Wybór odpowiedniego narzędzia zależy, w pewnym stopniu od indywidualnych preferencji użytkownika. Dla mnie decydującymi wskaźnikami w podjęciu decyzji są odpowiedzi na pytania:
- Czy ma więcej możliwości niż jest to konieczne, aby wykonać pracę na zakładanym poziomie. Innymi słowy, czy jest bardziej skomplikowany niż musi być?
- Czy jest łatwy w obsłudze?
- Czy wykonuje zadania w prawidłowy sposób? Czy brakuje mu jakiś funkcji?
Stosując się do powyższych kryteriów wybrałem i korzystam z edytora, który nazywa się HomeSite. Jest to pakiet komercyjny (początkowo był to program dostępny bezpłatnie na okres próbny). Wersję testową tego programu można pobrać ze stron Allaire. Pomimo, że jest dostępna wersja 4.5.1 stale używam wersji 4.0 ponieważ wykonuje wszystko co jest mi potrzebne. Cały kurs, z którego korzystamy, został napisany przy użyciu HomeSite 4.0.
Na stronach www znajduje się wiele list edytorów html do pobrania. Jednym z najbardziej znanych miejsc jest Tucows, który stosuje system oceny. Zwróć uwagę, że pomimo iż powerHTML jest pakietem bezpłatnym otrzymał najwyższą ocenę. Innymi słowy pakiet wcale nie musi kosztować fortuny. Jednak powerHTML daje ci tylko bardzo podstawowe możliwości, co możesz zobaczyć na poniższym przykładzie:

Jak widać nie oferuje on specjalnej pomocy przy wyborze znaczników, a tylko podstawowy edytor tekstowy z oknem do zarządzania projektami, które przedstawiono po lewej stronie, jest ono pomocne przy wyborze stron do edycji. Znaczniki są rozpoznawane przez program i wyświetlają się na ekranie w kolorach. Pakiet nie posiada systemu korygowania błędów w czasie pracy oraz systemu weryfikacji znaczników. Można przełączyć system automatycznie aby umożliwić wysłanie plików za pośrednictwem łączy na twoją stronę www. Prosty ale tani pakiet!
Zaletą pakietu HomeSite jest "pomoc" wbudowana do systemu:
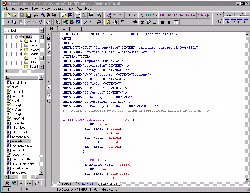
[Kliknij na ten mały obrazek aby zobaczyć powiększoną wersję.Przy okazji spotykamy się z problemem związanym z projektowaniem stron www: aby zobaczyć szczegóły potrzebny jest duży obraz, lecz wystarczające powiększenie obrazu powoduje zniszczenie ustawień tabeli, w której jest umieszczony tekst. Jedynym rozwiązaniem, które przychodzi mi do głowy, jest zrobienie połączenia od małego obrazka do jego wersji powiększonej.]
Jak można zauważyć, w prawym górnym rogu obrazka znajduje się kilkanaście przycisków. Dzięki nim, wszelkiego rodzaju znaczniki mogą być wprowadzane bezpośrednio do tekstu, np. symbol kotwicy umożliwia wstawienie odnośnika (link), a symbol znajdujący się obok tego przycisku jest przeznaczony do wstawiania obrazów. Te udogodnienia oznaczają, że możesz złożyć swoją stronę bardzo szybko.
Oferta dostępnych edytorów jest bardzo szeroka, lecz wybór należy do ciebie. Jak wspomniałem wcześniej zależy on zarówno od predyspozycji osobowych oraz ograniczeń, takich jak koszty czy standardy obowiązujące wewnątrz twojej organizacji.
| Do początku strony | Do strony domowej |
Projektowanie stron
Wprowadzenie
Chociaż wiele mówi nadal się o tym, że hipertekst i informacja cyfrowa różnią się zasadniczo od tradycyjnego druku, nie jest dziwne, że nadal mówimy o "stronach www" ponieważ faktycznie zasady prawidłowego projektowania stron www są oparte na zasadach prawidłowego projektowania stron "tradycyjnych". Ostatecznie mamy do czynienia z takimi samymi pojęciami jak krój pisma, stopień pisma, światło na stronie, długość linii oraz z innymi zagadnieniami mającymi zastosowanie zarówno w odniesieniu do tekstu na ekranie komputera, jak i do tekstu na papierze. Przykładowo, zwróć uwagę, że wiele stron oferujących bieżące wiadomości stosuje format, który ogranicza długość linii - np. Washington Post lub Independent czy Rzeczpospolita - można zauważyć, że powyższy kurs dzięki "obwódce" znajdującej się po lewej stronie także ogranicza długość linii. Zwróćcie uwagę na odsyłacz do opcji: "Wersja Przyjazna dla Drukarki" na stronach "Washington Post". Umożliwia to drukowanie bez ilustracji oraz tabeli, co często powoduje problemy w "komunikacji" pomiędzy przeglądarką a drukarką.
Jeden z najlepszych podręczników do tworzenia stron www jest dostępny na stronach Yale University - http://info.med.yale.edu/caim/manual/- jest to strona zajmująca się podstawami projektowania graficznego. Zwróć ponownie uwagę na krótsze linie tekstu, dzięki którym zwiększa się jego czytelność. Podążając za odsyłaczami umieszczonymi na tej stronie dostaniesz się do dalszej części podręcznika, notabene dostępnego także w postaci drukowanej. W sposób czytelny przedstawiono w nim podstawowe zasady projektowania. Można je streścić w kilku punktach:
- Używaj spójnej struktury wizualnej będącej wskazówką dla użytkownika. Przykładowo, możesz zaobserwować, że w tym kursie nagłówki na poszczególnych poziomach mają różny wymiar i różnią się kolorami. Jest to pomocne w odnalezieniu się w ogólnej strukturze danej lekcji. Koniec sekcji jest zasygnalizowany przez "Powrót do początku strony" lub do strony domowej oraz poziomą linię. Dół strony (według terminologii księgarskiej można go nazwać kolofonem) jest "skrawkiem", który dostarcza informacji podobnej do tej jaką można znaleźć na karcie tytułowej książki.
- Unikaj obszarów rozpraszających uwagę - to jest bardzo trudne na stronach komercyjnych, które opierają się na reklamie. Przykładowo, wracając do witryny Washington Post, można zauważyć, że mija trochę czasu zanim odnajdziemy nagłówki wiadomości. Na stronie umieszczono zbyt wiele elementów rozpraszających uwagę.
- Unikaj wielu zmian kroju i wielkości czcionki. Używając HTML bardzo łatwo tworzy się różne "efekty", co naraża na niebezpieczeństwo stosowania różnorodnych kombinacji. W rezultacie, często prowadzi to do tego, że istotne treści zostają zagubione.
- Pamiętaj, że normalny (przynajmniej na Zachodzie) proces czytania zaczyna się od strony lewej i biegnie ku prawej oraz z góry na dół. Wykorzystuj takie opcje, które ułatwiają przepływ tekstu, a nie cechy, które przeszkadzają w swobodnym czytaniu.
W tym miejscu, jeżeli chcesz dowiedzieć się więcej możesz wrócić do podręcznika, a także prześledzić przykłady dobrego projektowania stron, wskazane przez autorów.
ĆwiczenieWybierz dwie lub trzy strony www, a następnie przeanalizuj je pod kątem podanych powyżej kryteriów. |
Na marginesie powinienem zaznaczyć, że Jakob Nielsen, "guru" projektowania użytkowego jest przeciwny wykorzystywaniu "podręcznych" okien:
Otwieranie kolejnego okna w przeglądarce przypomina sprzedawcę odkurzaczy, który zaczyna prezentację od opróżnienia popielniczki na dywan klienta. Nie zanieczyszczaj mojego ekranu jakimikolwiek nowymi oknami, dziękuję (w szczególności odkąd obecne systemy operacyjne mają marną opcję zarządzania oknami), Jeżeli bedę potrzebował nowego okna to otworzę je sam! Projektanci otwierają nowe okna w przeglądarkach zgodnie z teorią, że to zatrzyma użytkowników na ich stronach. Otwarcie nowego okna często umyka uwadze użytkowników, w szczególności kiedy korzystają oni z małego monitora, gdzie okna są powiększone tak, że wypełniają cały ekran. W ten sposób użytkownik próbujący wrócić do źródła będzie zakłopotany widokiem poszarzałego przycisku "Powrót" (Back). [Jakob Nielsen's Alertbox, 30 maja 1999 r.: 10 najczęściej popełnianych błędów w projektowaniu stron www.op-10 New Mistakes of Web Design (Alertbox May 1999)
| Do początku strony | Do strony domowej |
Czy powinniśmy używać ramek?
W Internecie znajdziecie wiele serwisów, które wykorzystują ramki (ang. frames), pomimo tego wciąż prowadzona jest debata na temat prawdziwej użyteczności tej techniki. Podstawowym problem jest to, iż ramki nie są tak naprawdę językiem programowania, są raczej rozszerzeniem HTML, które pozwala na prezentowanie kolekcji stron w szczególny sposób - poprzez ładowanie z jednej strony głównej. Dlatego też ramki określają układ pewnej grupy stron, a nie strukturę pojedynczych dokumentów . Jeżeli jesteście bardziej zainteresowani ramkami, to na tej stronie znajdziecie więcej informacji na ten temat. Ramki nie były częścią pierwotnego standardu HTML, nie zostały one również wynalezione przez światowego potentata Microsoft, lecz przez firmę Netscape.
Ostatnio ramki zostały włączone do standardu HTML, szczegóły na ten temat opisuje dokument wydany przez W3C:
Ramki pozwalają autorowi przedstawić kilka dokumentów na jednym ekranie w tej samej chwili. Mogą one być przedstawiane w sposób niezależnych jak i zależnych od siebie . Dzięki zastosowaniu ramek autor może pewne dokumentu umieścić "na stałe" podczas gdy inne mogą być "przewijane", natomiast jeszcze inne dokumenty mogą być ładowane w innych ramkach. Dla przykładu, w jednej ramce może być wyświetlany statyczny baner, w drugiej ładuje się menu nawigacyjne, natomiast w trzeciej ramce ładowany jest główny dokument, który może być przewijany. Dodatkowo w trzeciej ramce mogą być ładowane inne dokumenty poprzez kliknięcie na menu znajdujące się w drugiej ramce. Oto prosty przykład :
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd"> <HTML> <HEAD> <TITLE>A simple frameset document</TITLE> </HEAD> <FRAMESET cols="20%, 80%"> <FRAMESET rows="100, 200"> <FRAME src="contents_of_frame1.html"> <FRAME src="contents_of_frame2.gif"> </FRAMESET> <FRAME src="contents_of_frame3.html"> <NOFRAMES> <P>This frameset document contains: <UL> <LI><A href="contents_of_frame1.html">Some neat contents</A> <LI><IMG src="contents_of_frame2.gif" alt="A neat image"> <LI><A href="contents_of_frame3.html">Some other neat contents</A> </UL> </NOFRAMES> </FRAMESET> </HTML><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd"> <HTML> <HEAD> <TITLE>prosty dokument z ramkami </TITLE> </HEAD> <FRAMESET cols="20%, 80%"> <FRAMESET rows="100, 200"> <FRAME src="ramka1.html"> <FRAME src="ramka2.gif"> </FRAMESET> <FRAME src="ramka3.html"> <NOFRAMES> <P>Ten dokument zawiera ramki: <UL> <LI><A href="ramka1.html">Zawartości ramki 1</A> <LI><IMG src="ramka2.gif" alt="Zawartości ramki 1"> <LI><A href="ramka3.html">Zawartości ramki 1;/A> </UL> </NOFRAMES> </FRAMESET> </HTML>A oto jak będzie wyglądał graficzny układ tych ramek:
--------------------------------------- | | | | | | | Ramka 1 | | | | | | | | |---------| | | | Ramka 3 | | | | | | | | | | | Ramka 2 | | | | | | | | | | | | | | ---------------------------------------
Oto przykłady serwisów WWW stworzonych przy użyciu ramek :
- Okropna strona - oto przykład strony umyślnie stworzonej przy wykorzystaniu ramek, której układ graficzny jest okropny. Kliknij na "Home Page", aby się dowiedzieć się jakie są właściwe rekomendacje projektanta tworzenia stron.
- Projekt Stanford Poynter . - oto inny ironiczny serwis "Jak użytkownicy czytają strony WWW".
Moim zdaniem w większości przypadków nie jest wskazane stosowanie ramek. Jeśli stosujemy je bez namysłu mogą się stać przyczyną różnych kłopotów. Największym z nich może wystąpić gdy w jednej z ramek link wskazuje dokument znajdujący się na innym, zewnętrznym serwerem. W tej sytuacji dokument ten może zostać załadowany nie na cały ekran lecz do małej, ciasnej ramki. Jeśli dodatkowo ładowany dokument jest również stworzony przy pomocy ramek, to na ekranie pojawi się kilkanaście małych ramek, w których dokumenty będą całkowicie nieczytelne.
Ramki mogą być bardzo skuteczne w wyświetlaniu pewnego określonego, skończonego zbioru dokumentów np. stron dostępnych w sieci Intranet, gdzie nie występują zewnętrzne linki. Ramki dodatkowo zapewniają doskonały sposób prezentowania informacji na stronie.
Jakob Nielsen, specjalista do spraw projektowanie serwisów WWW zgadza się z moją ogólną opinią na temat ramek. Dokument ten powstał cztery lata temu, ale myślę iż generalne tezy w nim zawarte są nadal aktualne.
| Do początku strony | Do strony domowej |
Tabele
Tabele są wykorzystywane w tworzeniu stron WWW do dwóch celów: po pierwsze, jako standardowa tabela, w której zamieszczone są jakieś dane. Oto przykład takiego zastosowania :
| Kategorie | Wielka Brytania 1998% | 1998% wg NG | 1997 % wg NG |
|---|---|---|---|
| 1. Istotne linki | 33.3 | 12.7 | 38.3 |
| 2. Linki typu 'Hot' | 11.2 | 25.4 | 10.0 |
| 3. Strony bez linków | 53.3 | 53.8 | 58.0 |
| 4. Linki reklamowe | 3.6 | 14.6 | 14.0 |
Z poniższego rysunku wynika, iż stworzenie nawet małej tabeli wymaga wprowadzenia dużej ilości tagów. Wykonanie bardziej złożonych tablic może być bardzo czasochłonne.

Innym zastosowaniem tablic jest formatowania tekstu na stronie. Właśnie ten dokument, jak i inne w tym kursie składają się z jednej tablicy wypełnionej tekstem. Jeśli klikniesz na "View", a później "Source" - pojawi się dodatkowe okienko zawierające kod źródłowy danej strony. W dokumencie tym, zaraz za tagiem <BODY>, znajduję się tag <TABLE> odpowiedzialny za tworzenie tablicy oraz określający jej parametry tj. grubość linii, szerokość kolumn i inne.
<TABLE>
<TR>
<TD bgColor=red width="12%> </TD>
<TD bgColor="white" vAlign=top width="12%"> </TD>
<TD bgColor="#ff8c8c" width=1%"> </TD>
<TD>
<TABLE cellPadding=10>
<TR>
<TD width="69%">
Na samym końcu strony znajduje się kilka tagów, które odpowiedzialne są za zakończenie tablicy:
</TD></TR> </TABLE>
powyższy tekst sygnalizuje, iż zakończyła się kolumna tabeli, wiersz kolumn oraz cała tabela.
Chociaż tablice są bardzo przydatne do organizowania tekstu na stronie, czasem jednak mogą one być przyczyną pewnych trudności. Podstawowym problemem może być drukowanie stron poprzez przeglądarkę WWW. Dlatego też w wielu serwisach znajdziemy link do strony w wersji "przyjaznej do drukowania".
| Do początku strony | Do strony domowej |
Identyfikacja
Bardzo ważne jest, aby czytający stronę www mógł stwierdzić kto jest autorem tekstu. Szczególnie w przypadku prowadzenia prac badawczych lub na stronach zawierających materiały szkoleniowe bądź informacyjne. Można zauważyć, że w dole tych stron znajdują się - można to nazwać "metryką drukarską" - informacje, które pojawiały się na książkach przed wymyśleniem strony tytułowej. Poniższą frazę odczytujemy.
Kurs przygotowany i przeprowadzony przez
Profesora Toma Wilsona
z Wydziału Studiów Informacyjnych Uniwersytetu w Shefffield w ramach projektu Tempus realizowanego we współpracy z
Międzynarodowym Centrum Zarządzania Informacją UMK w Toruniu oraz
Wydziałem Bibliotekoznawstwa i Studiów Informacyjnych University College w Dublinie.
Jak można zauważyć fraza zawiera odnośniki do mojej strony domowej (home page), do strony domowej mojego Wydziału, do strony domowej Międzynarodowego Centrum Zarządzania Informacją oraz do strony domowej Wydziału na Uniwersytecie w Dublinie. Innymi słowy, ty oraz każdy użytkownik tych stron znajdzie na nich więcej informacji o organizacjach oraz osobach zaangażowanych w przygotowanie tego kursu.
Na innych stronach, należących do czasopisma elektronicznego "Information Research" każdy artykuł posiada "metryczkę drukarską". Np.:
Działalność wydawnicza - Paul Kipling i T.D. Wilson Lokalizacja:
http://www.shef.ac.uk/~is/publications/infres/paper63.html © autorzy, 1999
Data ostatniej modyfikacji: 4 lipca 1999
Zamiast odnośnika do mojej strony domowej ta "metryczka" zawiera hiperłącze do adresu poczty elektronicznej (mailto), które automatycznie wyświetla okno poczty elektronicznej użytkownika umożliwiający wysłanie do mnie wiadomości. Kolejny odnośnik prowadzi do stron konkretnego numeru czasopisma, na których znajduje się artykuł.
Inne strony posiadają podobny rodzaj komunikatu umieszczony w "stopce", który zawiera: prawo własności, prawa autorskie, datę utworzenia oraz inne treści, np.:
National Computer Systems, Inc.
Wszystkie prawa zastrzeżone
1-800-431-1421
http://www.ncs.com
e-mail: info@ncs.com
Jakiekolwiek zaprojektujesz strony, czy dla potrzeb własnych czy organizacji, powinny zawierać taki komunikat aby umożliwić użytkownikowi właściwą identyfikację ciebie lub twojej organizacji.
| Do początku strony | Do strony domowej |
Używanie meta-tagów
Wewnątrz sekcji HEAD dokumentu hipertekstowego często można znaleźć tzw. "meta-tagi". Ich zadaniem nie jest opisywanie struktury zawartości dokumentu, lecz dokumentu jako całości. Można je porównać do indeksów lub klasyfikacji występujących w bazach danych. Szczególnym rodzajem meta-tagu jest META HTTP-EQUIV, którego zadaniem jest kontrolowanie przeglądarki WWW poprzez m.in. ustawianie cookies (ciasteczek), przekazywanie danych związanych z autoryzacją. Więcej informacji na ten temat można znaleźć na tej stronie.
Innymi przykładami "meta-tagów" są znaczniki typu META NAME=... CONTENT=..., które pozwalają dołączyć dodatkowe informacje opisujące dany dokument. Na przykład:
<META NAME="keywords" CONTENT="HTML, tables, meta-tags, page-design, browsers, frames">określa zbiór słów kluczowych opisujących zawartość danej strony. Tak określona dodatkowa informacja o zawartości strony wykorzystywana jest przez wyszukiwarki, aby dokładnie wyszukiwać odpowiednie do zapytania strony.
Szczególną specyfikacją "meta-tagów" jest "Dublin Core"
Składa się ona z piętnastu elementów :
- TITLE (tytuł) - nazwa danego zasobu nadana przez TWORCĘ lub PUBLICYSTĘ tego zasobu.
- AUTHOR ( autor) lub CREATOR (twórca) - osoba/y lub organizacje odpowiedzialne za informacyjną zawartość strony.
- SUBJECT (temat) lub KEYWORDS (słowa kluczowe) - temat lub słowa kluczowe opisujące zawartość dokumentu.
- DESCRIPTION (OPIS) - tekstowy opis zawartości dokumentu, zawierający m.in. główne cele lub założenia danego zasobu.
- PUBLISHER (wydawca) - jednostka odpowiedzialna za udostępnienie zasobu w aktualnej formie. może to być np. wydawca, wydział uniwersytetu lub jakaś firma komercyjna.
- OTHER CONTRIBUTORS(inny współtwórcy) - osoba/y lub organizacja/e, które poza twórcami strony wniosły swój wkład przy tworzeniu danego dokumentu.
- DATE (data) - data udostępnienia dokumentu w aktualnej formie.
- RESOURCE TYPE (rodzaj dokumentu) - kategoria dokumentu np. strona domowa, powieść, wiersz, notatka, raport techniczny , esej słownik. Wartość tego elementu powinna być wybrana z powyższej listy.
- RESOURCE IDENTIFIER (identyfikator zasobu) - ciąg znaków lub liczba, która w sposób unikalny określa daną stronę. Bardzo często wartością tego argumentu jest URL.
- SOURCE (źródło) - nazwa dokumentu w postaci drukowanej lub elektronicznej na podstawie, którego dany dokument hipertekstowy powstał.
- LANGUAGE (język) - język(i), w którym/ych został napisany dany dokument.
- RELATION - opisu relacje z innymi dokumentami. Format tego pola nie został jeszcze ustalony.
- COVERAGE - charakterystyka opisująca lokalizacją przestrzenną i czas trwania dokumentu. Format tego pola nie został jeszcze ustalony.
- RIGHTS MANAGMENT - zawartość tego argumentu powinien być link do pliku określającego prawa autorski i warunki kopiowania materiałów z danego dokumentu.
Składnia meta-tagów jest bardzo prosta. Oto schemat:
<META NAME = "Nazwa_elementu" CONTENT = "Wartość">
Przykładowe mata-tagi dla autora i tytułu mogą wyglądać następująco:
<META NAME = "DC.Title" CONTENT = "The War of the Worlds">
<META NAME = "DC.Creator" CONTENT = "H.G. Wells">
Jest wiele serwisów, które oferują automatyczne generowanie "meta-tagów": należy wpisać do formularza wartość danego elementu, kliknąć na przycisku zatwierdzającym i po chwili otrzymamy stronę przedstawiającą nasze meta-tagi zgodnie ze standardu HTML 4.0. Dodatkowo pewne serwisy posiada opcje przesłania stworzonego " meta-tagu" poprzez e-mail. Na obrazku poniżej przedstawiony został zbiór "meta-tagów" wygenerowany przez serwis Nordic Metadata Project:

Zauważmy jednak, iż oryginalna strona zwrócona przez Nordic Metadata Project zawiera dodatkowo linki do stron opisujących definicję każdego tagu. Nasz rysunek został wyczyszczony z tych dodatkowych linków, chociaż dobrze mieć pod ręką dokument na temat dokładnej specyfikacji "Doublin Core".
| Do początku strony | Do strony domowej |
Rejestrowanie przez wyszukiwarki
Nie ma sensu poświęcać czasu na tworzenie stron www jeżeli nikt ich nigdy nie odwiedzi! Pierwszym krokiem gwarantującym, że twoje strony będą odnalezione przez kogoś szukającego informacji związanych z twoją stroną jest być zauważonym przez wyszukiwarki. Oznacza to, że powinieneś się upewnić, iż twoje strony www są indeksowane przez jak najwyższą liczbę wyszukiwarek. W rozdziale 2 zostało powiedziane, że różne wyszukiwarki indeksują różną ilość stron www. W tej chwili FAST indeksuje najwięcej stron.
Oczywiście, możesz zgłosić istnienie twoich stron www bezpośrednio do wyszukiwarki. Wiele z nich posiada stronę, która to umożliwia: np. w lewym dolnym rogu strony głównej AltaVisty znajdziesz wskazówkę "Dodaj URL" (Add an URL). Klikając na nią otrzymasz stronę, która nie tylko pozwoli ci wprowadzić twój URL, ale także oferuje informacje co AltaVista robi, aby zagwarantować użyteczność swojego serwisu:
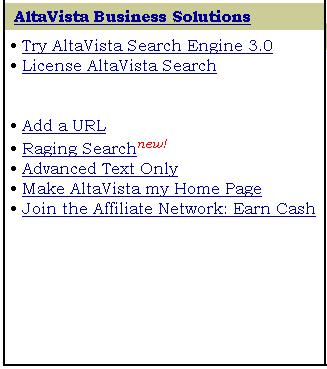
Celem AltaVisty jest dostarczanie właściwych rezultatów twoich poszukiwań. Aby zachować integralność indeksu oraz dostarczać właściwych wyników poszukiwań musimy czasami wykluczyć zgłoszenia stron, które używają technik manipulowania rezultatami wyszukiwań.
Czasami respektujemy przykłady takiej manipulacji, lecz nie dotyczy to:
- Stron, na których tekst jest nieczytelny, zarówno z powodu zbyt małej czcionki jak i zbyt zaciemniającego tła.
- Stron ze słowami kluczowymi nie związanymi z tematem.
- Powielania zawartości, zarówno nadmierne zgłaszanie tej samej strony, jak i zgłaszanie tej samej strony z różnymi domenami lub zgłaszanie tej samej treści z wielu komputerów głównych (hosts).
- Komputerowo generowanych stron z minimalną zawartością, bądź bez treści, których wyłącznym celem jest umożliwienie użytkownikowi kliknięcie aby przenieść się na inną stronę.
- Stron, które zawierają tylko odnośniki do innych stron.
- Stron, których głównym zamiarem jest skierowanie użytkownika do stron pod zmienionym adresem.
AltaVista dokłada starań, aby wyniki poszukiwań dostarczały dokładnych informacji o zawartości stron www. W związku z tym, rezerwujemy sobie prawo do usuwania i/lub odłączania odnośników do stron lub strony www, co do których AltaVista zdecyduje, zgodnie z jej uznaniem, że zostały powzięte niewłaściwe kroki w celu manipulowania wynikami wyszukiwań AltaVisty. W wypadku pytań i komentarzy odnośnie tej polityki lub zasad wprowadzania jej w życie prosimy o kontakt - e-mail: spam-support@av.com
Wypełnianie tego rodzaju stron we wszystkich wyszukiwarkach jest zajęciem nudnym. Nic dziwnego, że poszczególne serwisy wychodzą na przeciw z propozycją wykonania tej pracy za ciebie. Większość z nich wymaga opłat, ale niektóre dołączą twój URL do ograniczonej liczby wyszukiwarek bez opłaty, np. Submit Express dołączy twój URL do 40 wyszukiwarek bezpłatnie podczas gdy AddMe.Com tylko do 30. Z innej strony, serwis Gethits.com dołączy twój URL do 500 wyszukiwarek za opłatą - lecz za cenę możliwą do przyjęcia - na dzień dzisiejszy wynosi ona 89$. Oto ich cennik:
Zanim przyłączysz twój URL do wyszukiwarek powinieneś się upewnić, czy stronę zaprojektowano w taki sposób, że zostanie odnaleziona, kiedy ktoś podejmie wyszukiwanie, oraz czy zawiera wystarczającą ilość informacji pozwalających użytkownikowi ocenić, czy warto na nie zajżeć. SearchEngineWatch.com dostarcza informacji o działaniu wyszukiwarek oraz podpowiada, co zrobić, by osiągnąć założone cele. Zasadniczą sztuką jest znaleźć taki sposób, aby w wyniku wyszukiwań związanych tematycznie z twoimi stronami znaleźć się w pierwszej dziesiątce, wyświetlającej się użytkownikowi. SearchEngineWatch.com podaje:
"Na zapytanie zadane wyszukiwarce często w efekcie otrzymujemy setki tysięcy "odpowiednich" stron www. W większości wypadków na ekranie wyświetlanych jest tylko pierwszych 10 "właściwych" trafień. Naturalnie, każdy kto "uruchamia" strony www chciałby być w pierwszej dziesiątce ponieważ tam właśnie większość użytkowników znajduje odpowiadające im wyniki. Jeśli znajdziesz się na jedenastej lub dalszej pozycji wiele osób może nie trafić do twoich stron."
Kilka wskazówek oferowanych przez SearchEngineWatch.com:
- Wybór strategicznych słów kluczowych.
- Skuteczne umieszczenie słów kluczowych - tzn. w polu <TITLE> w nagłówku strony.
- Zamieszczenie odpowiedniej zawartości.
- Użycie odnośników html do innych stron, a nie tylko wskaźników w formie map bitowych.
- Ramki mogą przeszkadzać w dostępie do stron.
- Wykorzystaj meta znaczniki.
- Podłącz tylko swoje strony "kluczowe" a niekoniecznie wszystkie strony.
- Kontroluj i utrzymuj w porządku swoją listę - strony mogą zniknąć z indeksów wyszukiwarek.
Innymi słowy dowiedz się jak najwięcej o działaniu wyszukiwarek oraz zapoznaj się z ich wymaganiami zanim podłączysz swój URL.
| Do początku strony | Do strony domowej |
Śledzenie popularności naszego serwisu WWW
Skupiając swoją uwagę na zaprojektowaniu strony i zapewnieniu jej dobrej wyszukiwalności poprzez ustawienie meta-tagów, możemy zadawać sobie pytanie jak skutecznie nasz dokument jest wyszukiwany. Odpowiedź możemy otrzymać po zainstalowaniu licznika lub systemu do analizowania logów.
Liczniki - umieszczenie licznika na stronie WWW jest podstawową rzeczą, którą powinien zrobić autor dokumentu aby sprawdzić statystyki na temat używalności swoich strony. Wiele stron posiada liczniki, często są one umieszczony w taki sposób, iż przyciągają uwagę internautów bardziej niż informacje zawarte na stronie! Information Research używało już wielu typów liczników jednak ostatnio korzysta z darmowego serwisu MyComputer.com. NA samym dole tej strony znajdziecie przykład takiego licznika. Jak już mówiłem, w Internecie znajdziecie wiele serwisów, które udostępniają usługę "licznik WWW" - jest to jedyne rozwiązanie pozwalające na śledzenie wykorzystania serwisu WWW jeśli nie mamy bezpośredniego dostępu do serwera. Jeśli natomiast w pełni kontrolujesz swój serwer WWW, masz wystarczające prawa dostępu, możesz używać oprogramowanie licznika zainstalowanego lokalnie.
Analizy statystyczne. Słabą stroną statystyk zbieranych przez licznik jest to, iż podają one tylko ilość odwiedzin danej strony. Oczywiście chcielibyśmy otrzymać więcej informacji m.in. kto odwiedza nasz serwis, z jakich sieci i komputerów. Ten rodzaj informacji jest bardzo ważny szczególnie dla e-commerce, ponieważ dzięki tego typu informacjom wielkie koncerny przemysłowe nie muszą płacić za wykonywanie analiz rynku.
Na stronie Information Research - ircont.html znajdziemy klawisz połączony z licznikiem i serwisem zbierającym statystyki NedStat. Jeśli klikniesz na ten link zobaczysz, iż system ten dostarcza więcej informacji niż zwykły licznik : całkowita ilość odwiedzin - 42,538 (15 maja 2000), numery IP komputerów dziesięciu ostatnich osób odwiedzających stronę, odwiedzający w czasie jednej godziny, dnia i tygodnia, domeny z jakich oglądana była strona i inne. Lista ostatnich 25 odwiedzających daję możliwość otrzymania dalszych informacji na temat używalności tego magazynu - zobacz poniższy wykres:
Jeśli masz dostęp do serwera, na którym zamieszczone są twoje strony, możesz również skorzystać z systemu analizującego logi serwera WWW. Jak opisuje Jeffrey Rubin istnieje wiele takich systemów wykonujące różne ciekawe statystyki.
Dostępne jest nawet darmowe oprogramowanie Analog, którego autorem jest Stephen Turner z University of Cambridge Statistical Laboratory. Turner twierdzi, iż jest to najpopularniejsze oprogramowanie służące do zbierania statystyk serwera WWW. Program ten jest dostępny nie tylko w języku angielskim, ale również 300 innych językach, między innym w języku polskim.
Bez względu na to czy zdecydowałeś się już lub jeszcze nie na zainstalowanie liczników i systemu dokonującego analiz statystycznych, jest naprawdę ważne abyś to zrobił. Jeśli prowadzisz serwis komercyjny programy tego typu pomogą Ci w badaniu i poszukiwaniu nowych rynków. Jeśli jestem twórcą publicznego serwisu, którego tematem jest na przykład "możliwości rozwoju przemysłu" lub "turystyka", wtedy możesz zbierać informacje o użytkownikach, które w przeszłości mogą być wykorzystane do komunikowania z nimi za pomocą e-mail. Jednym słowem, systemy śledzące odwiedzanie naszego serwera WWW mogą być bardzo przydatne w celu przekonania zarządu naszej firmy, sponsorów, iż robimy coś bardzo ważnego.
| Do początku strony | Do strony domowej |
Znajdź więcej
Domyślasz się zapewne, że ogromna ilość informacji na tematy poruszane w tym kursie znajduje się w Internecie, a wiele wskazówek podano w trakcie poszczególnych lekcji. Wykorzystam nagłówki poszczególnych części lekcji jako punkty wyjścia do dalszych poszukiwań, dając przykładowo jedno lub dwa miejsca kluczowe do każdego tematu.
- Intranet - wiele odnośników znajdziesz w
the Intranet Journal i Intranet Design Magazine.
- "Języki" znaczników (Mark-up "languages") - poszczególne "języki" mają swoich entuzjastów i strony www, lecz kilka wartościowych stron zawiera
the Web Developer's Journal,
the Web Developer's Virtual Library i
Web Developer.com. Wszystkie razem oferują wskaźniki do setek źródeł.
- SGML - obszerny wybór odnośników znajduje się na stronach Robina Covera
The XML Cover Pages,
które pomimo nazwy zawierają informacje na temat SGML.
An Arbortext SGML "White Paper"
SGML: getting started może być szczególnie użyteczny
jako wprowadzenie. W tym samym miejscu dostępne jest także
SoftQuad's SGML Primer.
- HTML - doskonałe źródło informacji ogólnych na ten temat można znaleźć na
HTML Writers Guild.
Kliknij na przycisk "Resources" a znajdziesz o wiele więcej. Także
A beginner's guide to HTML (Podręcznik HTML dla początkujących) znajduje się na stronach NCSA na Uniwersytecie Illinois (gdzie stworzono pierwszą wyszukiwarkę - Mosaic). Podręcznik jest bardzo pomocny jako wprowadzenie.
W końcu Introduction to HTML (Wprowadzenie do HTML) przygotowane przez Allana Richmonda jest doskonałym podręcznikiem.
- XML - strona Roberta Covera
The XML Cover Pages jest najlepszym miejscem, aby zacząć;
jednym z odnośników jest
XML, Java and the future of the Web, strony stworzone przez Jana
Bosaka z Sum Microsystems.
- XHML - wydaje się, że oficjalnym miejscem jest
XHML.
- XHTML - XHTML.ORG jest spisem źródeł na ten temat.
Formalnym standardem jest
XHTML 1.0: The Extensible HyperText Markup Language. Przeformułowanie XTML 4 na XML 1.0. Zalecenie W3C z 26 stycznia 2000.
- Znalezienie dobrego edytora HTML -
TUCOWS jest doskonałym źródłem.
- Projektowanie stron - najlepsze źródło zostało już wymienione - Lynch P.J., Horton S., Web style guide, New Haven, CT: Yale University, Center for Advanced Instructional Media, 1997. Aczkolwiek jest o wiele więcej przydatnych miejsc. Możesz odszukać ich spis za pomocą wyszukiwarki
Google.
- Ramki czy bez ramek - oficjalnym miejscem jest
HTML 4.01 Specyfikacja. Zalecenie W3C z 24 grudnia 1999.
- Tabele - Pomocny podręcznik na temat tabel stworzony został przez
Urb LeJeune. Zakłada on korzystanie z Netscape'a, ale to nie wydaje się istotne.
- Korzystanie z metaznaczników -
How To Use HTML Meta Tags (Jak używać metaznaczników HTML). Jest to całkiem dobre miejsce aby zacząć; następnie dzięki Google search możesz znaleźć o wiele więcej.
- Rejestrowanie się w wyszukiwarkach - usługa bezpłatna umożliwiająca przyłączenie stron www (ograniczona do 40 wyszukiwarek) znajduje się na stronach
Submit Express i
www.submit-it.com